Information Theory SG by Dr. Akinori Tanaka on March 24, 2021
2021-03-25
セミナーレポート
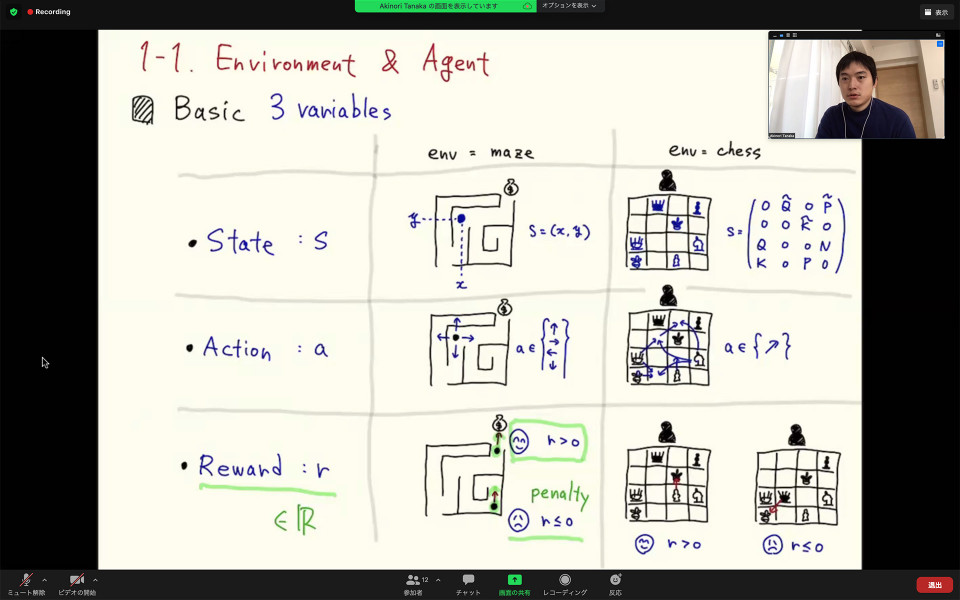
On 24th March, Dr. Akinori Tanaka gave an introduction to the reinforcement learning (RL) in our journal club of the Information Theory Study Group. He started from simple examples of a maze and a chess game to introduce the fundamental variables (i.e., states, actions, and rewards) and their evolution as a Markov decision process.After explaining that the goal of the RL is to maximize the value function, he discussed policy improvement theorem with the application to the epsilon-greedy update. We thank Akinori for the great and clear talk!
